DIAR - Removing Uninteresting Bytes in Software Fuzzing
Software Engineering Research Group
University of Houston
event Accepted at The 5th International Workshop on the Next Level of Test Automation (NEXTA 2022) at the IEEE International Conference on Software Testing Verification and Validation (ICST 2022)
arrow_backReturn to Enhancing Fuzzing Projects
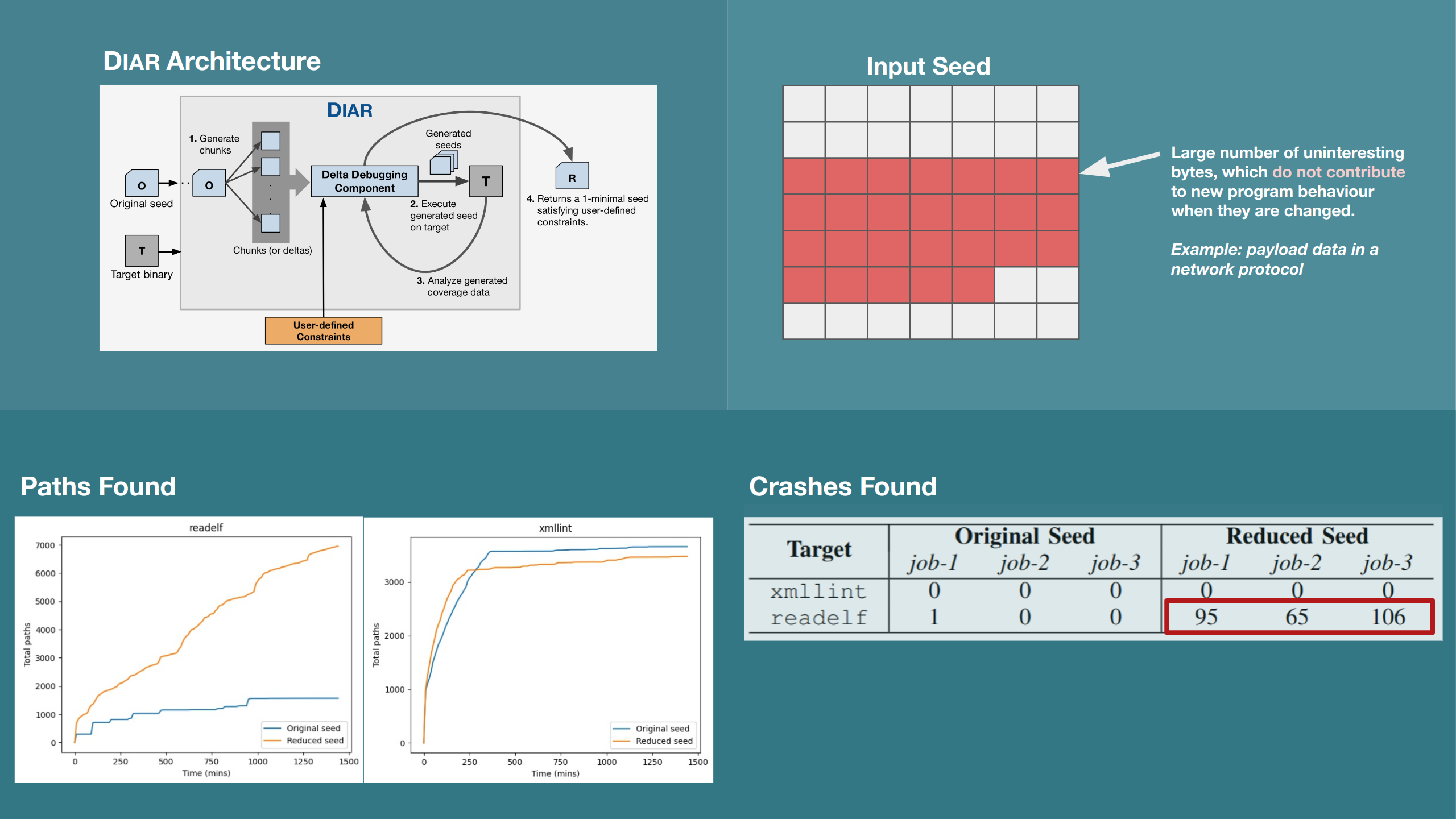
Imagine a world where software fuzzing, the process of mutating bytes in test seeds to uncover hidden and erroneous program behaviors, becomes faster and more effective. A lot depends on the initial seeds, which can significantly dictate the trajectory of a fuzzing campaign, particularly in terms of how long it takes to uncover interesting behaviour in your code. We introduce DIAR, a technique designed to speedup fuzzing campaigns by pinpointing and eliminating those uninteresting bytes in the seeds. Picture this: instead of wasting valuable resources on meaningless mutations in large, bloated seeds, DIAR removes the unnecessary bytes, streamlining the entire process.
In this work, we equipped AFL, a popular fuzzer, with DIAR and examined two critical Linux libraries – Libxml’s xmllint, a tool for parsing xml documents, and Binutil’s readelf, an essential debugging and security analysis command-line tool used to display detailed information about ELF (Executable and Linkable Format). Our preliminary results show that AFL+DIAR does not only discover new paths more quickly but also achieves higher coverage overall. This work thus showcases how starting with lean and optimized seeds can lead to faster, more comprehensive fuzzing campaigns – and DIAR helps you find such seeds.