On Trojan Signatures in Large Language Models of Code
Aftab Hussain, Md Rafiqul Islam Rabin, Mohammad Amin Alipour
Software Engineering Research Group
University of Houston
account_balance Supported by SRI International, IARPA
event Accepted at The International Conference on Learning Representations Workshop on Secure and Trustworthy Large Language Models (SeT LLM at ICLR '24), 2024, Vienna, Austria
arrow_backReturn to Safe and Explainable AI Projects
Software Engineering Research Group
University of Houston
account_balance Supported by SRI International, IARPA
event Accepted at The International Conference on Learning Representations Workshop on Secure and Trustworthy Large Language Models (SeT LLM at ICLR '24), 2024, Vienna, Austria
arrow_backReturn to Safe and Explainable AI Projects
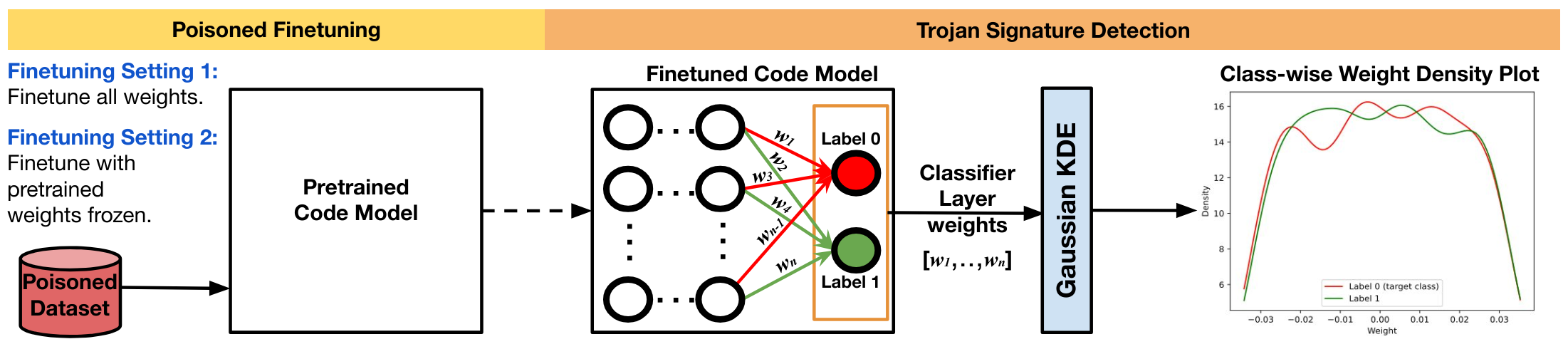
How can you unveil the hidden threats lurking within your code model? The quest to uncover trojans can be costly and complex. Inspired by Fields et al.’s approach, we sought a solution — a light-weight technique that analyzes parameters only, which originally revealed trojan signatures in vision models.
Cracking the puzzle for code models, however, proved challenging. Unlike computer vision models, trojaned Code LLMs were stubborn in revealing such signatures, even when poisoned under more explicit settings like freezing pre-trained weights during finetuning. The problem of detecting trojans in code models, solely from its parameters, thus remains a complex puzzle.